딥러닝을 공부하다 보면 Batch Normalizatoin이라는 기술을 접해봤을 것이다.
이 글은 Batch Normalization이 왜 등장했고 어떻게 작동 되는지 설명할 것이다.
Covariate Shift
Convariate Shift는 공변량 변화라 불리며, train data set과 validation data set의 데이터 분포가 다르게 나타나는 것을 의미한다.

Convariate shift는 validation data set을 추론할 때 성능에 영향을 미칠 수 있으며 제대로 된 성능평가가 불가능 해진다.
Internal Convariate Shift
Convariate Shift 현상이 DeepLearning Model의 매 layer 마다 일어나는 것이 Internal Convariate Shift이다.
Internal Convariate Shift는 모델의 깊이가 깊을 수록 심해지고 학습에도 영향을 끼친다.
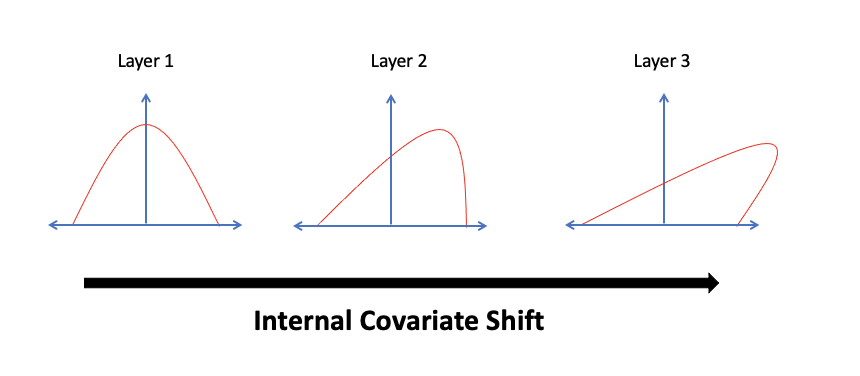
Batch Normlization는 위 현상을 막으려고 제안 됬고 발명되었다.
Batch Normalization
개념
- Batch Normalization은 학습과정에서 batch data별로 평균과 표준편차를 이용해서 정규화하는 것이다.
- Batch Normalization은 별도의 과정 없이 신경망과 같은 방식으로 사용 가능하다.
- 학습단계와 검증단계의 수행 방법이 다르다.
- 각 배치 데이터마다 평균은 0, 표준편차는 1로 정규화를 해준다.
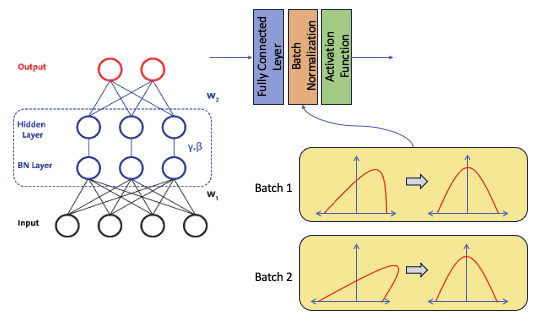
학습단계에서의 Batch Normalization
< 학습 단계의 BN 수식 >
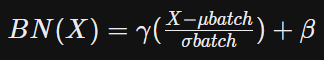
BN(X) = ɣ(X - μbatch / σbatch) + β
- X = 입력 데이터
- ɣ = 스케일
- β = 편향
- μbatch = batch 별 평균
- σbatch = batch 별 표준편차
여기서 ɣ과 β은 training 해야할 parameter로 사용한다. 두 parameter는 backpropagation을 통해 학습을 진행한다.
데이터 불균형과 gradient vanishing을 막기 위해 activation function 앞에 사용한다.
BN 작동 과정
1. Train data set의 mini batch 안에서 평균과 분산 및 표준편차를 계산

2. 입력 데이터에 대하여 각 data 별로 Normalization 수행

3. Normalization한 값들에 ɣ (scale)과 β(shift)를 추가

Scale Factor ( ɣ ) 와 Shift Factor ( β ) 의 기능
활성화 함수 Sigmoid가 있을 때, Normalization을 한 0~1 범위의 데이터가 들어온다고 하면 Sigmoid 함수 중간에 data가 많이 분포해 있을 것이다. Sigmoid 함수의 중간 구간은 선형이 되는 구간이기 때문에, non-linaer한 구조를 잃게 되며 DNN의 특성을 잃어버리게 된다.

하지만 Scale Factor ( ɣ )와 Shift Factor ( β )의 학습으로 non-linearity를 유지시킨다.
검증 단계의 Batch Normalization
< 검증 단계의 BN 수식>

BN(X) = ɣ( x - μBN / σBN ) + β
- X = 입력 데이터
- μBN = data의 지수 이동 평균
- σBN = data의 지수 이동 표준편차
검증 단계에서는 데이터에 대해 답을 내야하므로 평균과 분산을 구할 수 없다.
따라서, 검증 단계에 BN을 적용할 때는 지수 이동 평균과 표준편차를 사용한다.
learning late를 키워도 상관없다!!!
입력 데이터가 0~1 범위에 있기 때문에 가중치를 update하는 편차가 크지 않다.